 人气排行榜
人气排行榜
搜索引擎核心技术详解2—网络爬虫
从爬虫设计角度讲,优秀的爬虫应该具备高性能,好的可扩展性、健壮性和友好性。
从用户体验角度考虑,对爬虫的工作效果评价标准包括:抓取网页覆盖率、抓取网页时新性和抓取网页重要性。
抓取策略、网页更新策略、暗网抓取和分布式策略是爬虫系统至关重要的4个方面内容,基本决定了爬虫系统的质量和性能。
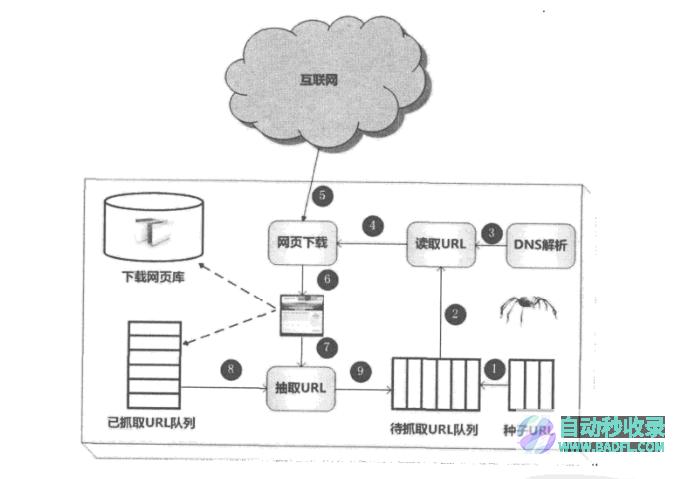
通用搜索引擎的处理对象是互联网网页,目前网页数量以百亿计,所以搜索引擎首先面临的问题就是:如何能够设计出高效的下载系统,以将如此海量的网页数据传送到本地,在本地形成互联网网页的镜像备份。
网络爬虫即起此作用,它是搜索引擎系统中很关键也很基础的构件。尽管爬虫技术经过几十年的发展,从整体框架上已相对成熟,但随着互联网的不断发展,也面临着一些有挑战性的新问题。
从爬虫开发者的角度考虑
分布式、并发性、数据中心
面对异常情况的处理、恢复
保护网站的私密性、减少被抓网站的网络负载
从搜索引擎用户体验的角度考虑
将新下载网页包含的链接直接追加到待抓取url队列末尾。很多新方法实际效果不见得比宽度优先更好。
实验表明这种策略效果很好,虽然看似机械,但实际上的网页抓取顺序基本是按照网页的重要性排序的。之所以如此,有研究人员认为:如果某个网页包含很多入链,那么更有可能被宽度优先遍历策略早早抓到,而入链个数从侧面体现了网页的重要性,即实际上宽度优先遍历策略隐含了一些网页优先级假设。
PageRank是一种著名的链接分析算法,可以用来衡量网页的重要性很自然地,可以想到用PageRank的思想来对URL优先级进行排序。 但是这里有个问题,PageRank是个全局性算法,也就是说当所有网页都下载完成后,其计算结果才是可靠的,而爬虫的目的就是去下载网页,在运行过程中只能看到一部分页面,所以在抓取阶段的网页是无法获得可靠PageRank得分的。
如果我们仍然坚持在这个不完整的互联网页面子集内计算PageRank呢?这就是非完全PageRank策略的基本思路:对于已经下载的网页,加上待抓取URL队列中的URL一起,形成网页集合,在此集合内进行PageRank计算,计算完成后,将待抓取URL队列里的网页按照PageRank得分由高到低排序,形成的序列就是爬虫接下来应该依次抓取的URL列表。这也是为何称之为“非完全PageRank”的原因。
非完全PageRank看上去相对复杂,那么是否效果一定优于简单的宽度优先遍历策略呢?
不同的实验结果存在争议,有些表明非完全PageRank结果略优,有些实验结果结论则恰恰相反。更有研究人员指出:非完全PageRank计算得出的重要性与完整的PageRank计算结果差异很大,不应作为衡量抓取过程中URL重要性计算的依据。
OCIP的字面含义是“在线页面重要性计算”,可以将其看做是一种改进的PageRank算法。
在算法开始之前,每个互联网页面都给予相同的“现金”(cash),每当下载了某个页面P后,P将自己拥有的“现金”平均分配给页面中包含的链接页面,把自己的“现金”清空。而对于待抓取URL队列中的网页,则根据其手头拥有的现金金额多少排序,优先下载现金最充裕的网页。
OCIP从大的框架上与PageRank思路基本一致,区别在于:PageRank每次需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度远远快于PageRank,适合实时计算使用。同时,PageRank在计算时,存在向无链接关系网页的远程跳转过程,而OCIP没有这一计算因子。
实验结果表明,OCIP是种较好的重要性衡量策略,效果略优于宽度优先遍历策略。
大站优先策略思路很直接:以网站为单位来衡量网页重要性,对于待抓取URL队列中的网页,根据所属网站归类,如果哪个网站等待下载的页面最多,则优先下载这些链接。其本质思想倾向于优先下载大型网站,因为大型网站往往包含更多的页面。鉴于大型网站往往是著名企业的内容,其网页质量一般较高,所以这个思路虽然简单,但是有一定依据。实验表明这个算法效果也要略优于宽度优先遍历策略。
本地下载的网页可被看做是互联网页面的“镜像”,爬虫要尽可能保证其一致性。爬虫要负责保持其内容和互联网页面内容的同步,这取决于爬虫所采用的网页更新策略。
历史参考策略是最直观的一种更新策略,它建立于如下假设之上:过去频繁更新的网页,那么将来也会频繁更新。所以,为了预估某个网页何时进行更新,可以通过参考其历史更新情况来做出决定。
这种方法往往利用泊松过程来对网页的变化进行建模,根据每个网页过去的变动情况,利用模型预测将来何时内容会再次发生变化,以此来指导爬虫的抓取过程。但是不同方法侧重不尽相同,比如有的研究将一个网页划分成不同的区域,抓取策略应该忽略掉广告栏或者导航栏这种不重要区域的频繁变化,而集中在主题内容的变化探测和建模上。
一般来说,搜索引擎用户提交查询后,相关的搜索结果可能成千上万,而用户没有耐心查看排在后面的搜索结果,往往只查看前3页搜索内容。用户体验策略就是利用搜索引擎用户的这个特点来设计更新策略的。
这种更新策略以用户体验为核心,即使本地索引的网页内容是过时的,但是如果不影响用户体验,那么晚些更新这些过时网页也未尝不可。所以判断一个网页何时更新为好,取决于这个网页的内容变化所带来搜索质量的变化(往往采用搜索结果排名的变化来衡量),影响越大的网页,则应该越快更新。
用户体验策略保存网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响,得出一个平均值,以此作为判断爬虫重抓该网页时机的参考依据,对于影响越厉害的网页,则越优先调度重新抓取。
上面介绍的两种网页更新策略严重依赖网页的历史更新信息,因为这是能够进行后续计算的基础。但是在现实中,为每个网页保存其历史信息,搜索系统会大量增加额外负担。从另外一个角度考虑,如果是首次抓取到的网页,因为没有历史信息,所以也就无法按照这两种思路去预估其更新周期。聚类抽样策略即是为了解决上述缺点而提出的。
聚类抽样策略认为:网页具有一些属性,根据这些属性可以预测其更新周期,具有相似属性的网页,其更新周期也是类似的。于是,可以根据这些属性将网页归类,同一类别内的网页具有相同的更新频率。为了计算某个类别的更新周期,只需对类别内网页进行采样,以这些被采样网页的更新周期作为类别内所有其他网页的更新周期。与之前叙述的两种方法相比较,这种策略一方面无须为每个网页保存历史信息;另一方面,对于新网页,即使没有历史信息,也可以根据其所属类别来对其进行更新。
相关实验表明,聚类抽样策略效果好于前述两种更新策略,但是对以亿计的网页进行聚类,其难度也是非常巨大的。
所谓暗网,是指目前搜索引擎爬虫按照常规方式很难抓取到的互联网页面。如前所述,搜索引擎爬虫依赖页面中的链接关系发现新的页面,但是很多网站的内容是以数据库方式存储的,典型的例子是一些垂直领域网站,比如携程旅行网的机票数据,很难有显式链接指向数据库内的记录,往往是服务网站提供组合查询界面,只有用户按照需求输入查询之后,才可能获得相关数据。所以,常规的爬虫无法索引这些数据内容,这是暗网的命名由来。
对于暗网爬虫来说,其技术挑战有两点:一是查询组合太多,如果一一组合遍历,那么会给被访问网站造成太大压力,所以如何精心组合查询选项是个难点;第二点在于:有的查询是文本框,比如图书搜索中需要输入书名,爬虫怎样才能够填入合适的内容?这个也颇具挑战性。
google对此提出了解决方案,称之为富含信息查询模板(InformativeQueryTemplates)技术。
为了描述一个职位,完整的查询由3个不同的属性构成:职位类别、行业类别和工作地点。Google的技术方案是如此定义的:对于某个固定的查询模板来说,如果给模板内每个属性都赋值,形成不同的查询组合,提交给垂直搜索引擎,观察所有返回页面的内容,如果相互之间内容差异较大,则这个查询模板就是富含信息查询模板。
职位类别有3种不同赋值,行业类别有2种不同赋值,两者组合有6种不同的组合方式,形成这个模板的6个查询。将这6个查询分别提交给职位搜索引擎,观察返回页面内容变化情况,如果大部分返回内容都相同或相似,则说明这个查询模板不是富含信息查询模板,否则可被认为是富含信息查询模板。
如果返回结果页面内容重复太多,很可能这个查询模板的维度太高,导致很多种组合无搜索结果,抑或构造的查询本身就是错误的,搜索系统返回了错误页面。
假设按照上面方式对所有查询模板一一试探,判断其是否富含信息查询模板,则因为查询模板数量太多,系统效率还是会很低。为了进一步减少提交的查询数目,Google的技术方案使用了ISIT算法。
ISIT算法的基本思路是:首先从一维模板开始,对一维查询模板逐个考察,看其是否富含信息查询模板,如果是的话,则将这个一维模板扩展到二维,再次依次考察对应的二维模板,如此类推,逐步增加维数,直到再也无法找到富含信息查询模板为止。通过这种方式,就可以找到绝大多数富含信息查询模板,同时也尽可能减少了提交的查询总数,有效达到了目的。
Google的评测结果证明,这种方法和完全组合方式比,能够大幅度提升系统效率。
在爬虫运转起来之前,因为对目标网站一无所知,所以必须人工提供一些提示。通过人工观察网站进行定位,提供一个与网站内容相关的初始种子查询关键词表,对于不同的网站,需要人工提供不同的词表,以此作为爬虫能够继续工作的基础条件。爬虫根据初始种子词表,向垂直搜索引擎提交查询,并下载返回的结果页面。之后从返回结果页面里自动挖掘出相关的关键词,并形成一个新的查询列表,依次将新挖掘出的查询提交给搜索引擎。如此往复,直到无法下载到新的内容为止。通过这种人工启发结合递归迭代的方式,尽可能覆盖数据库里的记录。
对于主从式分布爬虫,不同的服务器承担不同的角色分工,其中有一台专门负责对其他服务器提供URL分发服务,其他机器则进行实际的网页下载。URL服务器维护待抓取URL队列,并从中获得待抓取网页的URL,分配给不同的抓取服务器,另外还要对抓取服务器之间的工作进行负载均衡,使得各个服务器承担的工作量大致相等,不至于出现忙的过忙、闲的过闲的情形。抓取服务器之间没有通信联系,每个抓取服务器只和URL服务器进行消息传递。
Google在早期即采用此种主从分布式爬虫,在这种架构中,因为URL服务器承担很多管理任务,同时待抓取URL队列数量巨大,所以URL服务器容易成为整个系统的瓶颈。
初期:由于没有URL服务器存在,每台抓取服务器的任务分工就成为问题。由服务器自己来判断某个URL是否应该由自己来抓取,或者将这个URL传递给相应的服务器。至于采取的判断方法,则是对网址的主域名进行哈希计算,之后取模(即hash[域名]%m,这里的m对应服务器个数),如果计算所得的值和抓取服务器编号匹配,则自己下载该网页,否则将该网址转发给对应编号的抓取服务器。
因为有3台抓取服务器,所以取模的时候m设定为3。1号抓取服务器负责抓取哈希取模后值为1的网页,当其接收到网址www.google.com时,首先利用哈希函数计算这个主域名的哈希值,之后对3取模,发现取模后值为1,属于自己的职责范围,于是就自己下载网页:如果接收到网址www.baidu.com,哈希后对3取模,发现其值等于2,不属于自己的职责范畴,则会将这个要下载的URL转发给2号抓取服务器,由2号抓取服务器来进行下载。通过这种方式,每台服务器平均承担大约1/3的抓取工作量。
优点:由于没有URL分发服务器,所以此种方法不存在系统瓶颈问题,另外其哈希函数不是针对整个URL,而只针对主域名,所以可以保证同一网站的网页都由同一台服务器抓取,这样一方面可以提高下载效率(DNS域名解析可以缓存),另外一方面也可以主动控制对某个网站的访问速度,避免对某个网站访问压力过大。
缺点:假设在抓取过程中某台服务器宕机,或者此时新加入一台抓取服务器,因为取模时m是以服务器个数确定的,所以此时m值发生变化,导致大部分URL哈希取模后的值跟着变化,这意味着几乎所有任务都需要重新进行分配,无疑会导致资源的极大浪费。
改进:放弃哈希取模方式,转而采用一致性哈希方法(ConsistingHash)来确定服务器的任务分工。一致性哈希将网站的主域名进行哈希,映射为一个范围在0到2^32之间的某个数值,大量的网站主域名会被均匀地哈希到这个数值区间。将哈希值范围首尾相接,即认为数值0和最大值重合,这样可以将其看做有序的环状序列,从数值0开始,沿着环的顺时针方向,哈希值逐渐增大,直到环的结尾。而某个抓取服务器则负责这个环状序列的一个片段,即落在某个哈希取值范围内的URL都由该服务器负责下载。这样即可确定每台服务器的职责范围。
假设2号抓取服务器接收到了域名www.baidu.com,经过哈希值计算后,2号服务器知道在自己的管辖范围内,于是自己下载这个URL。在此之后,2号服务器收到了www.sina.com.cn这个域名,经过哈希计算,可知是3号服务器负责的范围,于是将这个URL转发给3号服务器。如果3号服务器死机,那么2号服务器得不到回应,于是知道3号服务器出了状况,此时顺时针按照环的大小顺序查找,将URL转发给第一个碰到的服务器,即1号服务器,此后3号服务器的下载任务都由1号服务器接管,直到3号服务器重新启动为止。
搜索引擎高级命令
搜索引擎核心技术详解10—网页去重
搜索引擎核心技术详解8—网页反作弊
搜索引擎核心技术详解6—链接分析
搜索引擎核心技术详解5—检索模型与搜索排序
搜索引擎核心技术详解3—搜索引擎索引
搜索引擎核心技术详解1—搜索引擎及其技术架构
搜索引擎工作原理介绍
知识像烛光,能照亮一个人,也能照亮无数人
搜索引擎发展简史
搜索引擎工作原理介绍
搜索引擎核心技术详解5—检索模型与搜索排序
相关标签: 搜索引擎核心技术详解2—网络爬虫、 SEO教程网、
本文地址:https://www.badfl.com/article/6b3fcd12f58604fa8079.html
<a href="https://www.badfl.com/" target="_blank">自动秒收录</a>
文章推荐















