 人气排行榜
人气排行榜
搜索引擎核心技术详解4—索引压缩
对于海量网页数据,为其建立倒排索引往往需要耗费较大的磁盘空间,尤其是一些比较常见的单词,其对应的倒排列表可能大小有几百兆。如果搜索引擎在响应用户查询的时候,用户查询中包含常见词汇,就需要将大量的倒排列表信息从磁盘读入内存,之后进行查询处理给出搜索结果。由于磁盘读/写速度往往是个瓶颈,所以包含常用词的用户查询,其响应速度会受到严重影响。索引压缩则可以利用数据压缩算法,有效地将数据量减少,这样一方面可以减少索引占用的磁盘空间资源,另一方面可以减少磁盘读/写数据量,加快用户查询的响应速度。
倒排索引主要包含两个构成部分:单词词典和单词对应的倒排列表。所以针对索引的压缩算法,也分为针对词典的压缩和针对倒排列表的压缩。而对倒排列表压缩又可以细分为无损压缩和有损压缩两种。所谓无损压缩,就是将原始倒排列表数据量减小,但是信息并不会因为占用空间的减小而有所损失,通过解压缩算法可以完全恢复原始信息。而有损压缩则是通过损失部分不重要的信息,以此来获得更高的数据压缩率。
为了快速响应用户查询,词典数据往往会全部加载到内存中,以加快查找速度。如果文档集合数据量很大,包含的不同单词数目会非常多,内存是否能够放得下全部词典信息就成了问题。为了减小词典信息所占内存,一般可考虑采用词典压缩技术来达到此目的。

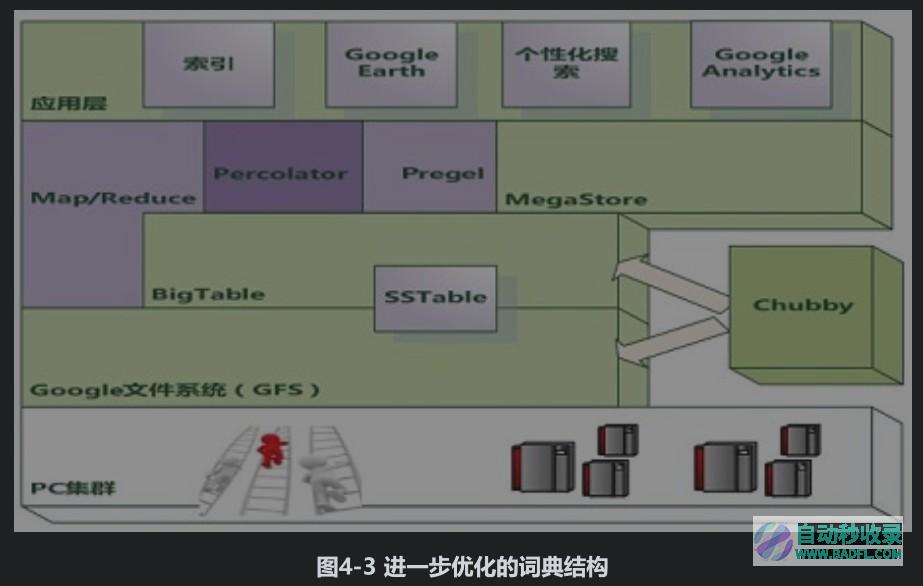
在上述优化词典结构的基础上,还可以继续做出改进,图4-3是进一步改进方案的示意图。其基本思想是:将连续词典进行分块,图中的例子是将每两个单词作为一个分块,在实际开发时,可动态调整分块大小,以获取最优压缩效果。原先每个词典项需要保留一个指向连续词典区的指针,而分块之后,相邻的两个词典项可以共享同一个指针,这样每两个词典项就节省出了一个4字节长的指针信息,因为此时连续词典分块内包含多个单词,为了能够标出其分隔位置,需要为每个单词增加单词长度信息,这样就可以在提取单词时对块内的不同单词予以正确区分。
实验表明,经过上述优化的词典比不做优化的词典占用内存数量减少了60%,可见这些优化措施还是非常有效的手段。
单词对应的倒排列表一般记载3类信息:文档编号、词频信息及单词位置序列信息。因为文档编号及单词位置序列是依次递增的,所以通常的做法是存储其差值,而非原始数据。经过差值转换,文档编号和单词位置信息往往会被转换成大量的小整数,而词频信息大部分是小整数,因为一个单词在正文中出现的频率通常都不高。压缩算法的处理对象就是这3类信息,从以上描述可以看出,倒排列表数据有其特点,即数字分布严重不均衡,小数值占了相当大的比例。
目前有很多种倒排列表压缩算法可供选择,但是评判算法的优劣需要定量指标。一般来说,评价倒排列表压缩算法会考虑3方面的指标:压缩率、压缩速度和解压速度。所谓压缩率,就是数据压缩前大小和压缩后大小的比例关系,很明显,压缩率越高,就越节省磁盘空间,同时也节省了倒排列表从磁盘读入到内存的I/O时间。压缩速度是指压缩一定量的数据所花费的时间,相对而言,这个指标不如其他两个指标重要,因为压缩往往是在建立索引过程中进行的,而建立索引是一个后台运行过程,不需要即时响应用户查询,即使速度慢些也没有太大关系。另外,建立索引的次数相对而言也不算多,所以从几个方面考虑,压缩速度不是一个重要指标。解压速度在3个指标中是最重要的,其含义是将压缩数据再次恢复为原始数据所花费的时间。因为搜索引擎在响应用户查询时,从磁盘读入的是压缩后的数据,需要实时解压以快速响应用户,所以解压速度直接关系到系统的用户体验,其重要性不言而喻。
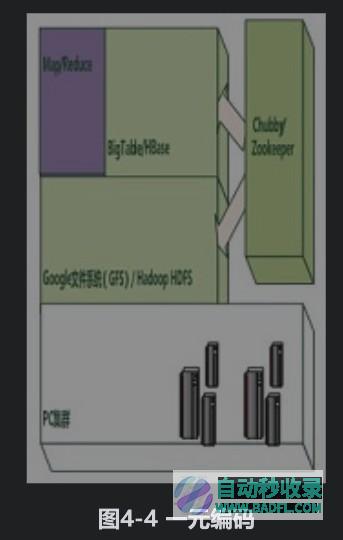
一元编码(UnaryCode)和二进制编码(BinaryCode)是所有倒排列表压缩算法的基本构成元素,不论压缩算法内部逻辑思路是怎样的,最终都要以这两种格式来对数据进行表示。要么是以一元编码和二进制编码混合的方式,要么是单独以二进制编码的方式。可以认为这两种编码格式是压缩算法的基础构件。一元编码是非常简单直观的数据表示方式,对于整数X来说,使用X-1个二进制数字1和末尾一个数字0来表示这个整数。图4-4是1到5这几个数字相对应的一元编码。可以看出,一元编码仅仅适合表示非常小的整数,比如对于数字23000,如果用一元编码表示明显是很不经济的。
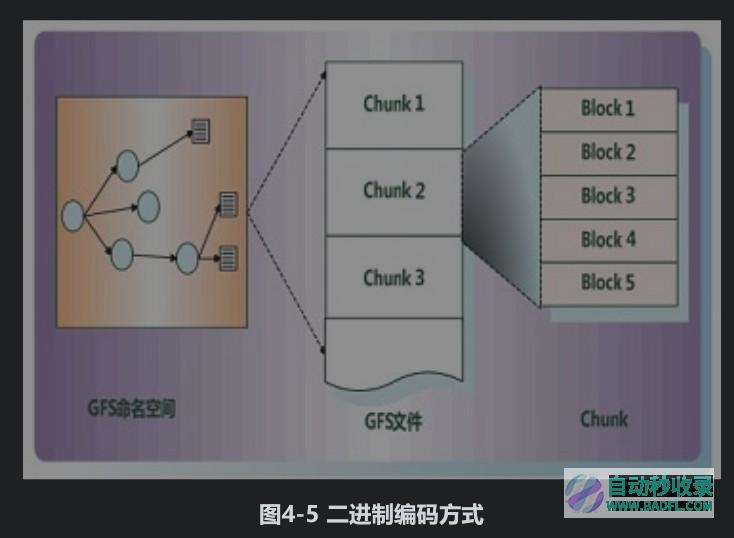
二进制表示方式是计算机内部的标准数据存储方式,即由二进制数字0和1进行组合来表示实际的数据。不同的比特宽度代表了不同的数字表示范围,图4-5给出了不同的比特宽度能够表达的数值范围及一些对应的二进制表示示例。比如对于比特宽度为3的情形,即用3个比特位来表示数字,那么其能够表达的数值范围为0到7这8个数字;对于数字5来说,将3个比特位设置为二进制101的方式就能够获得表达,其他例子与此相同。在计算机内部,一般是以字节为单位的,即比特宽度为8的二进制编码就是一个字节。相对于一元编码来说,只要比特宽度足够长,那么二进制编码可以表示几乎任意范围的数字。
了解了一元编码和二进制编码这两个压缩基础构件,我们下面介绍一些经典的倒排列表压缩算法
EliasGamma压缩算法利用分解函数将待压缩的数字分解为两个因子,之后分别用一元编码和二进制编码来表达这两个因子。EliasGamma算法采用的分解函数如下。x=2ed其中,x为待压缩的数字,e和d分别为其因子,得到分解因子后,对于因子e1采用一元编码来表示,对于因子d采用比特宽度为e的二进制编码来表示。假设待压缩的数字为9,因为9可以分解为2的3次方加1,所以e=3而d=1,对e1用一元编码后为:1110,而对d用比特宽度为3的二进制编码进行转换后为001,将两者拼接获得:1110:001,此即为数字9对应的EliasGamma编码。EliasDelta算法是建立在EliasGamma算法基础上的改进,在概念上可以认为是利用两次EliasGamma算法,将待压缩的数字分解为3个因子,之后利用一元编码和二进制编码来进行数值压缩。对于待压缩数字x,EliasDelta算法根据分解函数,将其分解为因子e和因子d,对因子d采用比特宽度为e的二进制编码进行压缩,而对于因子e1,则使用EliasGamma算法再次进行压缩,即分解出另外两个因子。
由此过程可以看出,Delta算法等于使用了两次EliasGamma算法,将待压缩数字分解为3个因子,然后分别编码获得最后的压缩数据。我们仍然以数字9来说明EliasDelta的编码过程。根据分解函数可知,e=3而d=1,对d利用3比特宽度的二进制编码压缩为001,对e1即数字4采用EliasGamma算法获得编码110:00,将两者拼接获得最终压缩编码为110:00:001。从以上两个压缩算法的过程可以看出,EliasDelta算法对于大数值来说压缩效果要优于EliasGamma算法。 Golomb算法和Rice算法在大的思路上也与上述的两个Elias算法类似,即根据分解函数将待压缩数值分解为两个因子,分别用一元编码和二进制编码来进行数据压缩表示。不同点在于,它们采用了和Elias算法不同的分解函数。
对于待压缩数值X,Golomb和Rice算法采用了如下的因子分解方式:
因子1是将X减1后除以参数b向下取整后获得的整数,将其值加1然后采用一元编码压缩;而因子2则是对参数b进行取模运算,获得取值范围在0到b-1之间的X除以b后的余数,对因子2使用二进制编码进行压缩,因为取模运算决定了其取值范围一定在0到b-1之间,所以二进制编码的比特宽度设定为log(b)就能表示这个范围内的数值。对于Golomb算法和Rice算法来说,b如何取值是其关键,这两个算法的不同点也仅仅在于b的不同取值方式。b的取值依据是什么呢?b的设定依赖于待编码数值序列的平均值或者中位数,在此基础上,Golomb和Rice算法对b的设定采取了不同的策略,假设一个待压缩数值序列的平均值为Avg,则Golomb算法设定为:b=0.69×Avg;这里的0.69是个经验参数,而Rice算法则要求b一定要为2的整数次幂,同时b必须是所有小于平均值Avg的2的整数次幂的数值中最接近Avg的数值。假设Avg的数值为113的话,则b会被设定为64,因为如果是128,则超过了113,如果是32,则此值不是小于113且最接近113的数值,只有64符合这些条件。图4-6给出了利用Golomb算法和Rice算法对待压缩数值序列进行压缩的示例。首先,获得数值序列的平均值133,Golomb算法设定b=78,其二进制编码的比特宽度可以取6或者7,即对在0到77范围内的数值,如果因子分解后因子2的值小于50,则采取6比特宽度,如果因子2的值大于50则采取7比特宽度,这样可以有效减少压缩数据的大小;而Rice算法设定b=64,其二进制编码的比特宽度取6。当这些参数都可以确定下来后,即可对数值进行压缩编码,我们以数值144为例说明,首先对其减去1,即需要对143进行压缩。对于Golomb算法来说,其对应的因子1取值为1,数值加1后采用一元编码得到10,因子2取值为65,对其进行二进制编码得到1000001,拼接两者获得最终编码10:1000001。对于Rice算法来说,143对应的两个因子分别为2和15,对2加1后进行一元编码得到110,对15进行二进制编码得到001111,拼接两者得到最终编码110:001111。对于Rice算法来说,之所以要设定b为2的整数次幂,是为了在具体实现算法时能够采取掩码操作或者比特位移操作等快速运算方式,所以Rice在运算效率方面要高于Golomb算法。而对设定好的参数b来说,其适用范围可以是局部的也可以是全局的,所谓全局的适用范围,就是说确定好b后所有单词对应的倒排列表都采用同一个数值;而所谓局部的适用范围,则是不同单词的倒排列表采取不同的参数b。一般来说,如果索引非常庞大,则采取局部参数b效果更好,原因也很明显,因为局部参数b等于是对待编码序列根据局部分布情况进行自适应调整,这样会使得压缩效果更好。

变长字节算法以字节(即比特宽度为8)为一个基本存储单位,而之前介绍的压缩算法都是变长比特算法,即以比特位(Bit)作为基本存储单位。之所以称之为“变长字节”,是因为对于不同的待压缩数字来说,在压缩编码后占用的字节数目不一定相同,可长可短,是变化的。一个字节包含8个比特位,因为对于变长字节算法来说,每个数字压缩后的字节数目是变动的,为了确定两个连续数字压缩后的边界,需要利用字节中一个比特位作为边界判断符号,一般如果边界判断比特位设定为0,则可以认为这个字节是数字压缩编码的最后一个字节,而如果设定为1,则说明后续的字节仍然属于当前的压缩数据数字。所以每个字节在概念上被划分为两部分,其中一个比特位用来做边界判断;其他7个比特位采用二进制编码来存储压缩数据,即每个字节的数值表示范围为128个数字。给定一个数值,如何对其进行变长字节压缩?图4-7给出了数值33549的变长字节压缩示例,因为一个字节可表示的数值范围为0到127,所以按照128作为基数将待压缩数值进行分解,分解后的因子分别为2、6和13,则在相应的字节存储这几个因子的二进制编码,同时设置边界指示位置为1、1和0,即说明这个数值需要3个字节来进行存储。

对于多个连续待压缩数值,则每个数值依照上例进行压缩编码,将其压缩编码连续存储即可。图4-8给出了多个连续数值序列对应的变长字节编码序列。
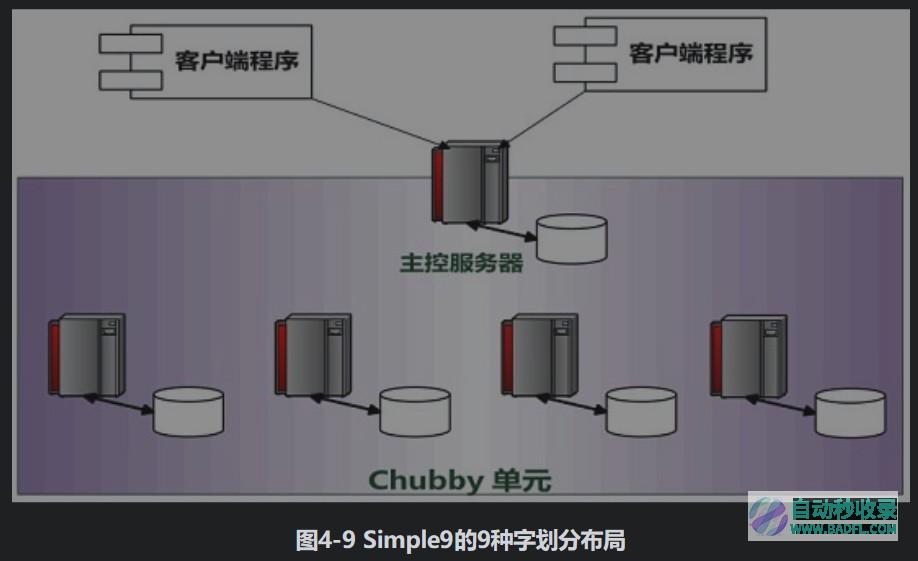
对于B为2的情况,数据存储区基本构成单元比特宽度为2,即数据存储区由14个2比特位基本单元拼接而成,因为2比特位可以表达4个数字,所以这种类型的布局,在一个32位比特字中,可以存储14个范围在0至3的数字。类似地,还可以根据B的不同大小设置其他的布局方式,图4-9给出了9种不同的布局,这里要注意的是:对于有些宽度的基本构成单元,因为不能被28整除,所以在数据存储区会有字节被废弃不用。比如对于B为3的情况,则最后一位比特位被废弃(图中有网线的单元指出了在各种情况下废弃的比特位)。在利用Simple9对数据进行压缩时,首先读取待压缩数值队列后续的28个数字,如果发现这28个数字都是0或者1,那么说明可以利用B=1这种布局来存储,则将28个数字编码为二进制后存入28个数据位,同时在类型指示位标出这种类型。如果发现有大于1的数值,说明B=1这个布局无法容纳这组数据,于是由读取后续28个数字改为读取后续的14个数字,判断是否能够使用B=2这种布局,即判断后续14个待压缩数据是否都在0到3的数值范围,如果是的话则采取B=2布局压缩,否则继续考虑B=3的布局,依次如此试探,即可将待压缩数字都表示为固定长度为32位比特的压缩表示方式。
利用Simple9进行解码的时候,因为编码是固定长度的,所以可以一次读取4个字节(即32比特),从4比特类型指示位判断后续数据存储区是哪种布局方式,对于每种布局方式可以事先准备好对应的掩码,判断出布局方式后,直接利用掩码可以一次性解压出后续的多个压缩数字。Simple16等后续改进算法在Simple9基础上做出了改进,改进思路大致相同。首先,Simple9的类型指示位由4比特位构成,即说明其可以指示16种不同情况,而Simple9因为只有9种类型,所以并未完全利用这4比特指示位置,可以将9种布局进行扩展,扩展为更多种布局方式,Simple16就是将后续28位数据存储区划分为16种组成方式。另外一点,从图4-9可以看出,Simple9在有些布局方式下会有废弃比特位,而这明显是对存储资源的浪费,可以考虑如何将其利用起来。Simple9之所以会出现废弃位,是因为它对28位数据存储区是等宽度划分的,所以必然会有无法被28整除而出现的废弃位。Simple16等改进算法则放宽了这种要求,即数据存储区不一定是等宽的,比如对于Simple9的B=5的状况,可以划分为4个5比特及后续的两个4比特,这样就利用Simple9进行解码的时候,因为编码是固定长度的,所以可以一次读取4个字节(即32比特),从4比特类型指示位判断后续数据存储区是哪种布局方式,对于每种布局方式可以事先准备好对应的掩码,判断出布局方式后,直接利用掩码可以一次性解压出后续的多个压缩数字。Simple16等后续改进算法在Simple9基础上做出了改进,改进思路大致相同。首先,Simple9的类型指示位由4比特位构成,即说明其可以指示16种不同情况,而Simple9因为只有9种类型,所以并未完全利用这4比特指示位置,可以将9种布局进行扩展,扩展为更多种布局方式,Simple16就是将后续28位数据存储区划分为16种组成方式。另外一点,从图4-9可以看出,Simple9在有些布局方式下会有废弃比特位,而这明显是对存储资源的浪费,可以考虑如何将其利用起来。Simple9之所以会出现废弃位,是因为它对28位数据存储区是等宽度划分的,所以必然会有无法被28整除而出现的废弃位。Simple16等改进算法则放宽了这种要求,即数据存储区不一定是等宽的,比如对于Simple9的B=5的状况,可以划分为4个5比特及后续的两个4比特,这样就
知识像烛光,能照亮一个人,也能照亮无数人
搜索引擎发展简史
搜索引擎工作原理介绍
搜索引擎核心技术详解5—检索模型与搜索排序
相关标签: 搜索引擎核心技术详解4—索引压缩、 SEO教程网、
本文地址:https://www.badfl.com/article/1bd9bd75938d25476bdb.html
上一篇:搜索引擎核心技术详解10网页去重...
下一篇:网络营销推广的三大方向...
<a href="https://www.badfl.com/" target="_blank">自动秒收录</a>
文章推荐















