 人气排行榜
人气排行榜
hbase是一种什么数据库 (hbase是什么)
Apache HBase 是一个基于 Apache Hadoop 的分布式、面向列的开源 NoSQL 数据库。它专为管理海量数据而设计,特别适合存储稀疏数据。
HBase 的特点
面向列: 数据以列簇组织,而不是行。这使得对特定列的访问非常高效,即使这些列跨多行。分布式: HBase 部署在集群中,数据跨所有节点分布。这确保了高可用性和可扩展性。可靠: HBase 使用多副本机制,确保数据在节点故障的情况下保持完整性。可扩展: HBase 可以轻松地扩展集群以满足不断增长的数据需求。高吞吐量: HBase 的设计使其能够处理大量读写操作,使其成为大数据分析和实时应用程序的理想选择。HBase 的应用场景
HBase 广泛应用于以下场景:大数据分析: 存储和处理海量数据,用于数据挖掘、机器学习和数据仓库。社交网络: 存储用户数据、活动和关系,用于实时社交分析和个性化推荐。IoT 设备: 存储和管理物联网设备产生的数据,用于设备监控和预测性维护。金融业: 存储和分析财务记录、交易数据和客户信息,用于风险管理和欺诈检测。零售业: 存储产品目录、客户购买历史和推荐,用于个性化购物体验和动态定价。HBase 的结构
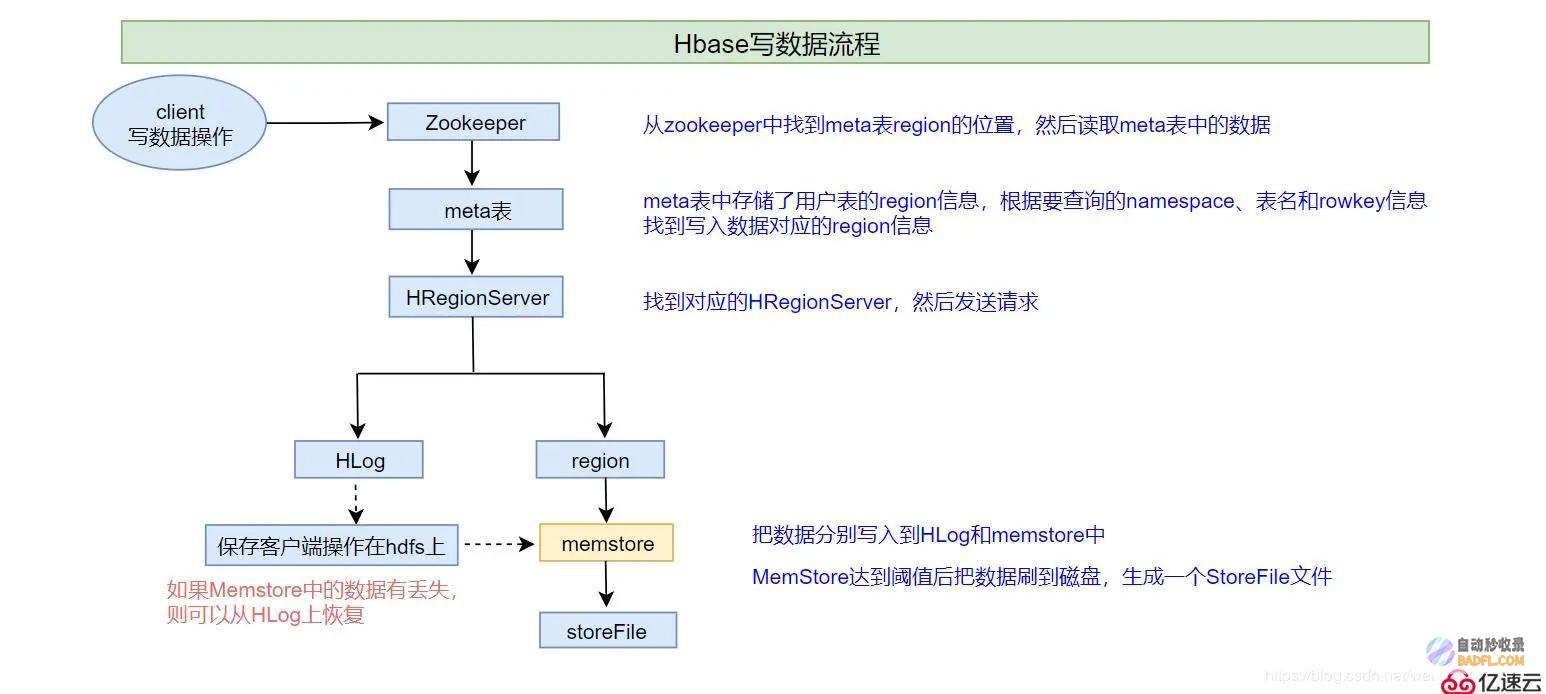
HBase 存储数据在表中,表由行和列簇组成:行: 标识数据的唯一键。它可以是任何字符串或字节数组。列簇: 相关列的集合。列簇内的数据类型可以不同。列: 列簇内的单个属性。它由列族和列限定符组成。单元格:存储特定行、列和时间戳的数据值。HBase 的优势
高性能: 面向列设计和分布式架构确保了快速的数据访问和处理能力。可扩展性: HBase 可以轻松地扩展到数千个节点,以满足不断增长的数据要求。可靠性: 多副本机制和数据容错特性确保了数据的完整性,即使在节点故障的情况下。灵活的数据模型: 灵活的数据模型允许存储各种类型的数据,包括文本、二进制和JSON。开放源码: HBase 是开源的,免费提供,使其成为具有成本效益的选择。HBase 的劣势
复杂性: HBase 的安装和管理比传统关系数据库更复杂,需要专门的专业知识。数据一致性: HBase 提供最终一致性,而不是强一致性,这对于某些应用程序可能不是理想的。有限的查询语言: HBase 的查询语言(HQL)相对有限,这可能限制了某些复杂查询的能力。内存消耗: HBase 需要大量内存来缓存数据,这可能会对资源有限的系统造成负担。高写入延迟: 由于 HBase 的数据复制机制,写入操作可能会产生高延迟。结论
HBase 是一个强大的 NoSQL 数据库,专为管理海量稀疏数据而设计。其面向列的设计、分布式架构和高性能使其非常适合大数据分析、社交网络和 IoT 应用。它也存在一些劣势,例如复杂性、有限的查询语言和高写入延迟。HBase 是需要处理和分析海量数据的组织的理想选择。HBase简介
HBase,全称为Hadoop Database,是一个专为大规模结构化存储而设计的分布式存储系统。 它以其高可靠性、高性能和可伸缩性而知名,能够在低成本的PC服务器集群上构建起强大的数据存储平台。
HBase是Google Bigtable开源的实现,其底层架构借鉴了Bigtable的设计。 Bigtable利用GFS作为文件存储系统,而HBase则选择Hadoop HDFS作为其存储基础。 在数据处理方面,Google Bigtable借助MapReduce进行海量数据操作,HBase同样采用Hadoop MapReduce来执行高效的数据处理任务。 在协同服务上,Bigtable使用Chubby,而HBase则依赖Zookeeper来提供稳定的服务和故障切换机制。
在Hadoop生态系统中,HBase位于结构化存储层,与底层的Hadoop HDFS紧密合作,后者为其提供了稳定的存储保障。 同时,Hadoop MapReduce为其提供了强大的计算能力,确保数据处理的高效性。 此外,Pig和Hive这两种高级语言接口,使得在HBase上进行数据统计和分析变得简单易行。 而Sqoop工具则简化了从关系型数据库(RDBMS)导入数据到HBase的过程,使得数据迁移变得更加便捷。
通过这些特性,HBase为用户提供了灵活、高效且易于管理的大规模数据存储解决方案。扩展资料HBase是一个分布式的、面向列的开源数据库,该技术来源于Chang et al所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。 就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。 HBase是Apache的Hadoop项目的子项目。 HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。 另一个不同的是HBase基于列的而不是基于行的模式。
hbase是一种什么数据库
HBase是一个基于Apache Hadoop的面向列的NoSQL数据库,是Google BigTable的开源实现。
它运行在HDFS之上,为Hadoop提供类似于BigTable规模的服务。 HBase针对半结构化数据,是一个多版本的、可伸缩的、高可靠的、高性能的、分布式的和面向列的动态模式数据库。
它采用了BigTable的数据模型增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。 HBase提供了对大规模数据的随机、实时读写访问。
HBase的目标是存储并处理大型的数据,即仅用普通的硬件配置,就能够处理上千亿的行和几百万的列所组成的超大型数据库。 HBase上的数据是以二进制流的形式存储在HDFS上的数据块中的,对于HDFS来说,HBase上的存储数据是透明的。
HBase的应用场景:
1、大型数据存储:HBase可以处理PB级别的数据量,适合存储大规模的数据,例如日志数据、监控数据、交易数据等。
2、时序数据:HBase可以用于存储时序数据,如速度的展示,天气、温度、风速、车流量等。
3、对象存储:HBase可以作为中等对象存储,对HDFS存储文件起到缓冲过渡的作用,减轻了NAMENODE元数据维护的压力。
4、消息/订单存储:因为HBase提供低延时、高并发的访问能力,所以可以用于电商平台等场景的消息和订单存储。
5、金融方面:HBase可以用于存储消费信息、贷款信息、信用卡还款信息等。
6、电商方面:可以用于存储淘宝的交易信息、物流信息、浏览信息等。
hbase和传统数据库的区别
数据存储方式不同、适用场景不同。 HBase是一种分布式、面向列的NoSQL数据库,而传统数据库通常是基于关系模型的关系型数据库。 这两种数据库在数据存储方式上有所区别。 HBase采用了列式存储的方式,将数据按列存储,适合存储大规模、稀疏的数据。 传统数据库则采用了行式存储,将数据按行存储,适合存储结构化的数据。 由于存储方式的不同,HBase在读取和查询大规模数据时具有较高的性能优势,而传统数据库在处理事务和复杂查询时较为擅长。 此外,HBase和传统数据库在适用场景上也有所区别。 HBase适用于需要高扩展性和高可用性的场景,如大数据分析、日志处理等。 它可以处理海量数据,并具备分布式存储和自动数据复制等特性。 传统数据库则适用于事务处理和关系型数据的应用场景,如企业管理系统、电子商务平台等。 它提供了强大的事务支持和复杂查询功能。
相关标签: hbase是一种什么数据库、 hbase是什么、
本文地址:https://www.badfl.com/article/67d2f582367c64548e74.html
<a href="https://www.badfl.com/" target="_blank">自动秒收录</a>
文章推荐















