人气排行榜
人气排行榜
搜查引擎如何抓取互联网页面 (搜查引擎如何关闭)

先说说搜查引擎的原理吧。
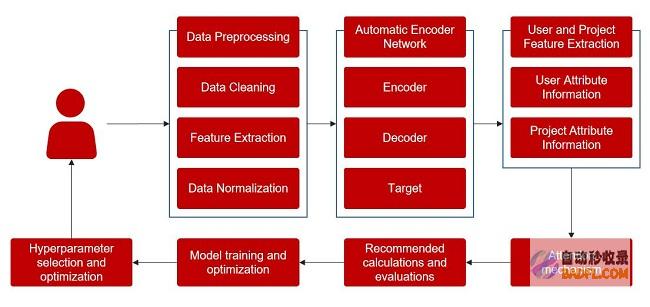
搜查引擎是把互联网上的网页内容存在自己的主机上,当用户搜查某个词的时刻,搜查引擎就会在自己的主机上找关系的内容,这样就是说,只要保留在搜查引擎主机上的网页才会被搜查到。
哪些网页能力被保留到搜查引擎的主机上呢?只要搜查引擎的网页抓取程序抓到的网页才会保留到搜查引擎的主机上,这个网页抓取程序就是搜查引擎的蜘蛛.整个环节分为匍匐和抓取。
一、蜘蛛
搜查引擎用来匍匐和访问网站页面的程序被称为蜘蛛,也可称之为机器人。
蜘蛛访问阅读器,就和咱们往常上网一个样子,蜘蛛雷同会放开访问,获取准许后才可以阅读,可是有一点,搜查引擎为了提高品质和速度,它会放很多蜘蛛一同去匍匐和抓取。
蜘蛛访问任何一个网站时,都会先去访问网站根目录下的文件。
假设文件制止搜查引擎抓取某些文件或目录,蜘蛛将遵守协定,不抓取被制止的网址。
和阅读器一样,搜查引擎蜘蛛也有标明自己身份的代理称号,站长可以在日志文件中看到搜查引擎的特定代理称号,从而辨识搜查引擎蜘蛛。
二、跟踪链接
为了抓取网上尽量多的页面,搜查引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就如同蜘蛛在蜘蛛网上匍匐一样。
整个互联网是有相互链接的网站及页面组成的。
当然,因为网站及页面链接结构意外复杂,蜘蛛须要采取必定的匍匐战略能力遍历网上一切页面。
最繁难的匍匐的战略有:深度优先和广度优先。
1、深度链接
深度优先指当蜘蛛发现一个链接时,它就会顺着这个链接指出的路不时向前匍匐,直到前面再也没其余链接,这时就会前往第一个页面,而后会继续链接再不时往前匍匐。
2、广度链接
从seo角度讲链接广度优先的意思是讲的蜘蛛在一个页面发现多个链接的时刻,不是跟着一个链接不时向前,而是把页面上一切第一层链接都爬一遍,而后再沿着第二层页面上发现的链接爬向第三层页面。
从实践上说,无论是深度优先还是广度优先,只需给蜘蛛足够的期间,都能爬完整个互联网。
在实践上班中,没有什么物品是有限的,蜘蛛的带宽资源和蜘蛛的期间也是一样都是有限的,也无法能爬完一切页面。
实践上最大的搜查引擎也只是匍匐和收录了互联网的一小局部。
3.吸引蜘蛛
蜘蛛式无法能抓取一切的页面的,它只会抓取关键的页面,那么哪些页面被以为比拟关键呢?有以下几点:
(1)网站和页面权重
(2)页面降级度
(3)导入链接
(4)与首页点击距离
4.地址库
搜查引擎会建设一个地址库,这么做可以很好的防止产生过多抓取或许重复抓取的现象,记载曾经被发现还没有抓取的页面,以及曾经被抓取的页面。
(1)人工录入的种子网站。
(2)蜘蛛抓取页面后,从HTML中解析出新的链接URL,与地址库中的数据启动对比,假设是地址库中没有的网址,就存入待访问地址库。
(3)搜查引擎自带的一种表格提供站长,繁难站长提交网址。
冰斗踢红蜘蛛软件限度上网怎样办
可以临时封锁软件,卸载软件,改换网络。
1、临时封锁软件:在义务栏中找到该软件的图标,右键点击并选用“分开”或“封锁”,而后再尝试上网。
2、卸载软件:假设封锁软件有效,可以尝试卸载该软件,详细操作可参考该软件的卸载指南。
3、改换网络:假设该软件限度了您以后衔接的网络,可以尝试衔接其余网络,如移动热点、公共Wi-Fi等。
蜘蛛如何结网
1、蜘蛛先在一棵树上找到适合的立脚点,引出许多根长度足以抵达对面的长丝。
蜘蛛网往往织在两根树枝或许相似的比拟空的中央,蜘蛛会应用气流,站在下风口,放出一根或几条比拟黏的线,借着风力,让这个线飘到另一边,蜘蛛丝很轻,即使风很小也没疑问。
而后蜘蛛会不时地碰触这些线来觉得这些线能否拉紧,判别这根线能否固定好了。
固定好之后,蜘蛛会爬上这根丝线。
2、而后,蜘蛛用脚去触触蛛丝的固着点。
假设有哪一根丝拉不动了,那么这根丝就曾经缠在对面的树上,“天索”架成了。
像房子的栋梁一样,它在这条定作为蜘蛛网的撑持线上,来来回回再粘几条丝,把它弄成一条粗“缆”。
3、接着,蜘蛛又在这条粗“缆”下方,平行地架设第二条“缆索”。
4、蜘蛛爬来爬去,网就在这两条“缆索”上架起来了。
相关标签: 搜查引擎如何抓取互联网页面、
本文地址:https://www.badfl.com/article/d49653fc9dc6b4749afe.html
<a href="https://www.badfl.com/" target="_blank">自动秒收录</a>
文章推荐