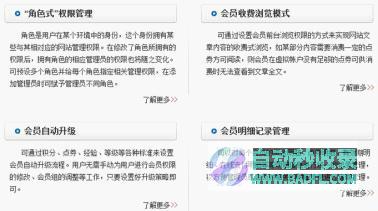
人气排行榜
人气排行榜
AI人工智能数据预处理技术
恭喜您成为首批注册用户
下面介绍数据预处理技术-
这是当需要将数值转换为布尔值时使用的预处理技术。我们可以用一种内置的方法来二值化输入数据,比如说用0.5作为阈值,方法如下-
现在,运行上面的代码后,将得到以下输出,所有高于 这是机器学习中使用的另一种非常常见的预处理技术。基本上它用于消除特征向量的均值,以便每个特征都以零为中心。还可以消除特征向量中的特征偏差。为了对样本数据应用平均去除预处理技术,可以编写如下Python代码。代码将显示输入数据的平均值和标准偏差- 运行上述代码行后,将得到以下输出- 现在,下面的代码将删除输入数据的平均值和标准偏差- 运行上述代码行后,将得到以下输出- 这是另一种数据预处理技术,用于缩放特征向量。特征向量的缩放是需要的,因为每个特征的值可以在许多随机值之间变化。换句话说,我们可以说缩放非常重要,因为我们不希望任何特征合成为大或小。借助以下Python代码,我们可以对输入数据进行缩放,即特征矢量- 运行上述代码行后,将得到以下输出- 这是另一种数据预处理技术,用于修改特征向量。这种修改对于在一个普通的尺度上测量特征向量是必要的。以下是可用于机器学习的两种标准化- 它也被称为最小绝对偏差。这种标准化会修改这些值,以便绝对值的总和在每行中总是最多为 上面的代码行生成以下输出: 它也被称为最小二乘。这种归正常化修改了这些值,以便每一行中的平方和总是最多为 执行以上代码行将生成以下输出- 更多建议: 违法和不良信息举报电话:173-0602-2364| 本文地址:https://www.badfl.com/article/15eaa8919a7f17ecb1b2.html0.5(阈值)的值将被转换为1,并且所有低于0.5的值将被转换为0。1。它可以在以下Python代码,使用上面的输入数据来实现-1。它可以在以下Python代码,使用上面的输入数据来实现-

相关标签:
AI人工智能数据预处理技术、
<a href="https://www.badfl.com/" target="_blank">自动秒收录</a>
文章推荐